
Full-stack inference optimization services.
Unlock the full value of generative and agentic AI with better architecture, better economics, and better execution.

An holistic approach to AI optimization.
Building on our expertise in model optimization, hardware-agnostic workload orchestration, and multi-model reasoning, we work with clients to improve the economics, performance, and business impact of AI at scale.
We help enterprises design, optimize, and scale high-performance AI systems to deliver better economics, performance, and business impact. Cut inference cost and latency while maximizing quality with an optimized, portable, data-driven AI inference stack.
Our services

Inference Cost & Performance Assessment
We assess your current inference environment to identify practical opportunities to reduce cost, lower latency, improve utilization, and optimize total cost of ownership.

Inference Benchmarking & KPI Strategy
We define and implement the benchmarks, KPIs, and dashboards needed to measure inference cost, latency, throughput, quality, and reliability, helping teams prove ROI and scale with confidence.
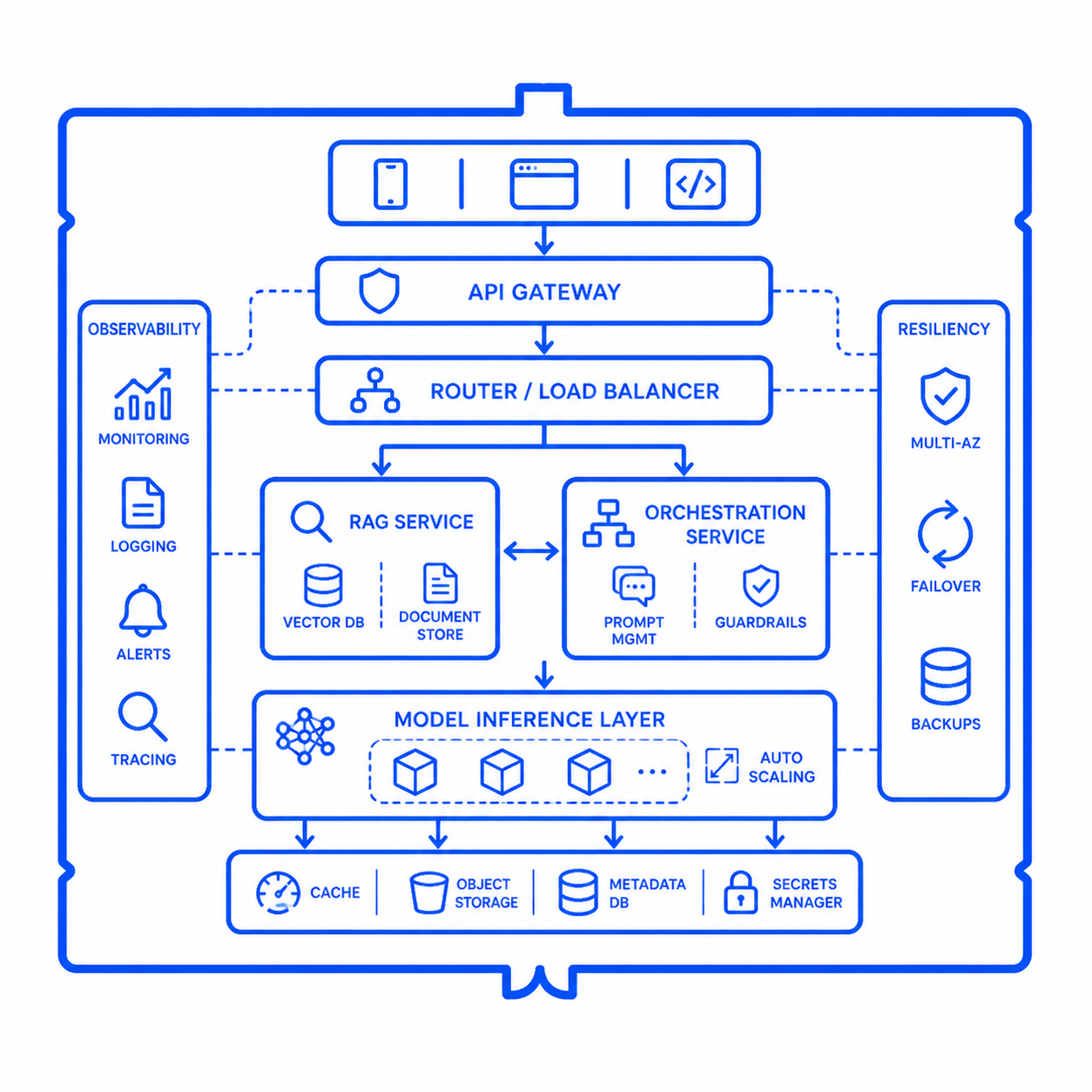
Inference Platform Reference Architecture
We design production-ready GenAI inference architectures, including gateways, routing, RAG, orchestration, autoscaling, and resiliency patterns engineered around your performance and reliability goals.
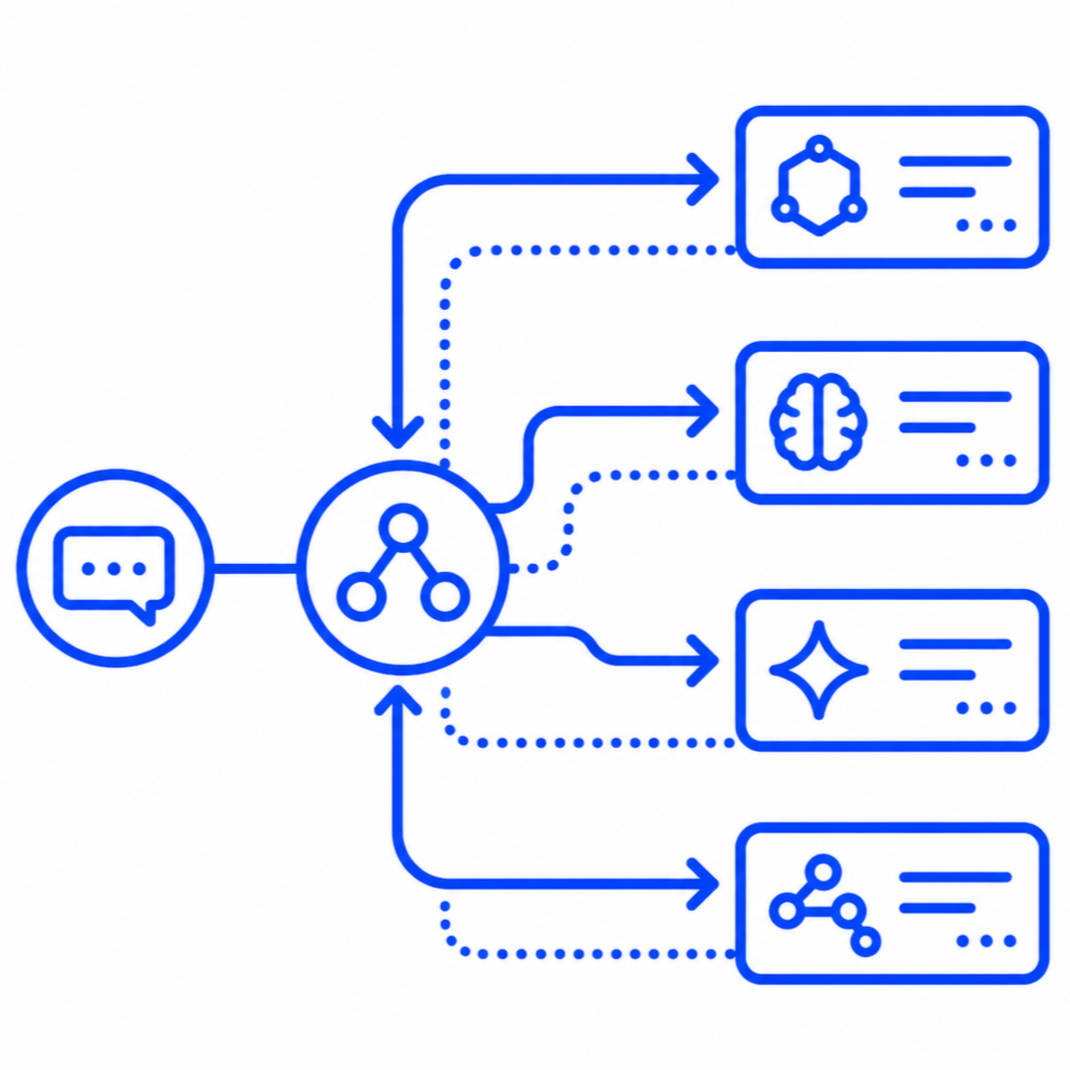
Model Routing & Orchestration Strategy
We help organizations design smart model routing, cascade, and fallback strategies that match each request to the right model while balancing quality, cost, and latency.
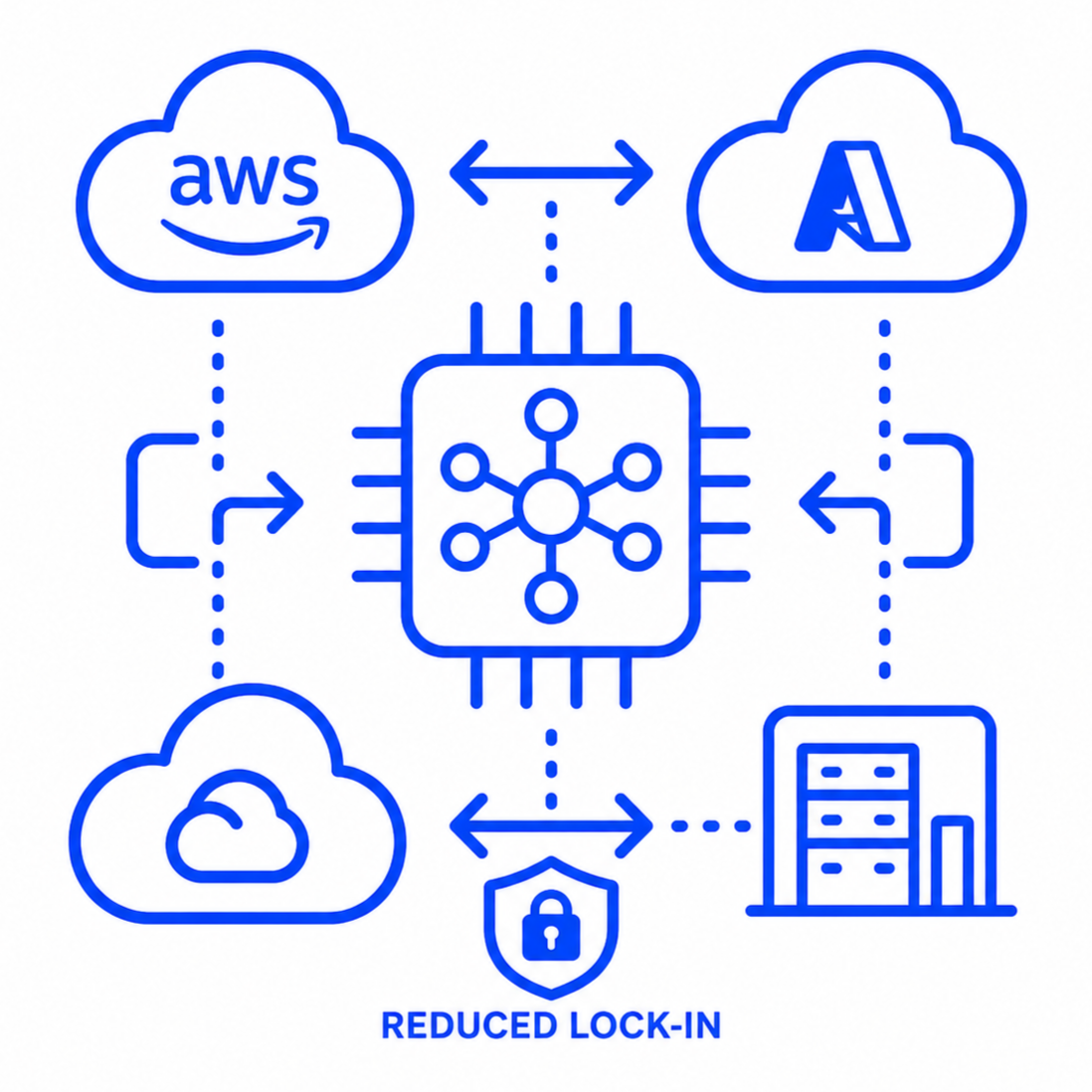
Hybrid & Multi-Cloud Inference Portability Strategy
We help enterprises create portable inference strategies across clouds, accelerators, and hybrid environments, reducing vendor lock-in and enabling future model and platform flexibility.
