
Cut your AI spend by 50% at scale.
We guarantee it.
Our impact
-

We optimize compute utilization for AI workloads
-

We cut down on power needed for compute and cooling
-

We reduce the need to build additional data center facilities
Choose your compute.
Cogniware enables compute platform independence.
Run scalable AI workloads on CUDA, x86, x64, Stream, and Tensor Core processors.
Choose your model.
Choose from up to 50 pre-packaged transformer models from the best AI companies. Or bring your own model with fine-tuning and guardrails. Train and run models, in parallel, on a single compute cluster.
Or run CogniDREAM multi-model inference (MMI™) for the most intelligent outputs.


CogniDREAM. The power of multi-model inference.
One model = smart.
Multiple models = super intelligent.
CogniDREAM (Dual Reasoning Engine for Assigning Models) harnesses the power of multiple optimized models – enabling them to reason together, automatically delegate knowledge-based training, and dynamically orchestrate inference.
Cogniware. Our unique middleware for compute virtualization and parallelization.
Patent-pending technology.
Years in development.
Makes running transformer models up to 70% more cost-effective.
Cogniware delivers optimized parallel processing for complex generative AI use cases. It dynamically creates and manages multiple compute nodes to continuously execute AI workloads with maximum efficiency.
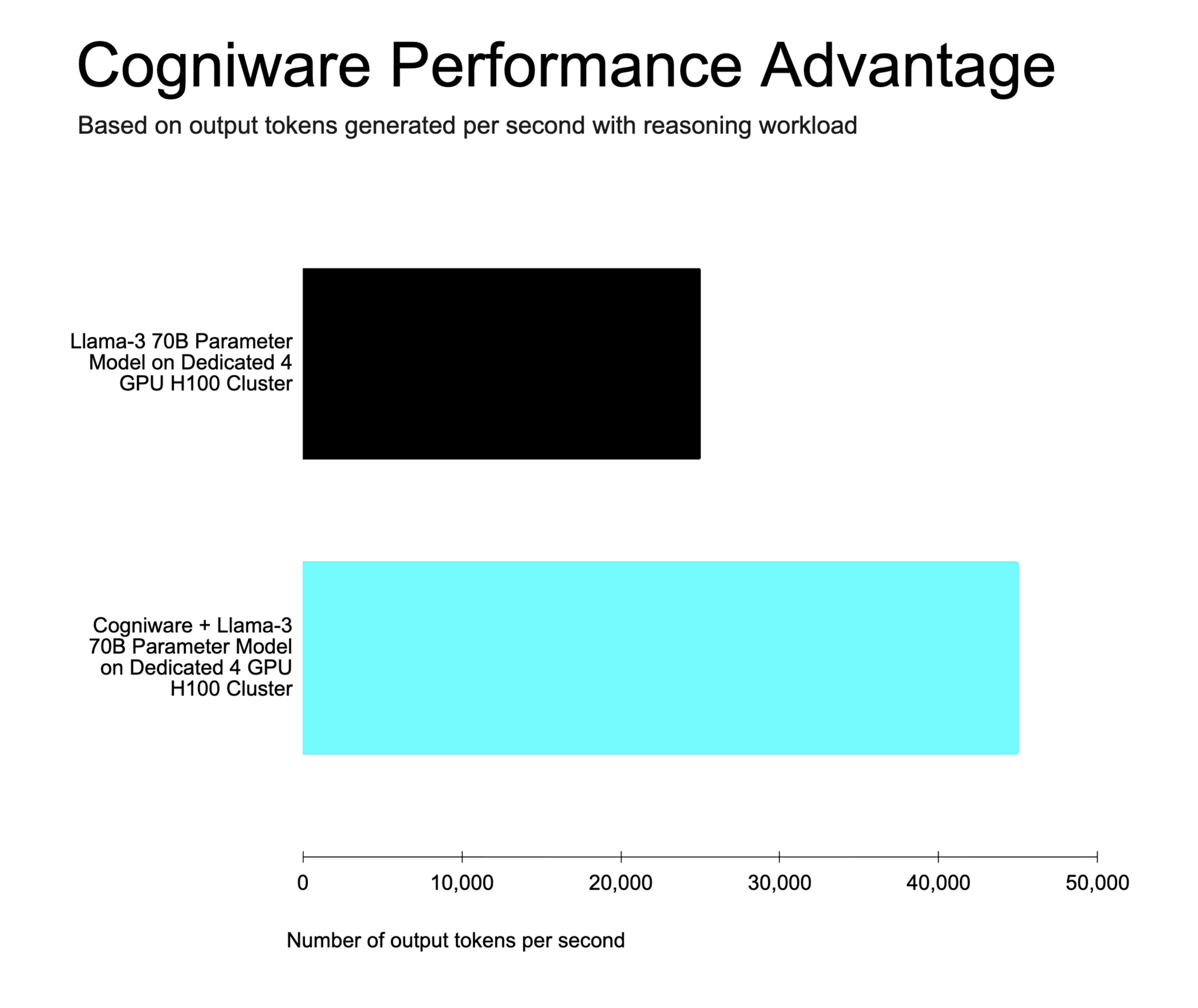
Internal Cogniware benchmarks using identical compute and LLM. Contact us for additional benchmarks.
A typical enterprise colocation facility has 1000 to 5000 GPUs
Approximately $60,000 for NVidia HGX B200; lower-end GPUs cost less
Typically $0.08 to $0.20
Typically 14.3 kW for a complete system of 8 NVidia HGX B200 GPUs
Typically 20-50% additional electricity over GPU draw
Typically $5M - $7M per year 1000 GPUs
More powerful GPUs support higher workloads but cost more to reserve
Typically $3-$4 for Nvidia HGX B200 from an AI cloud provider
